Scraping pipelines online
BUYMA Research Navi — Web Scraping
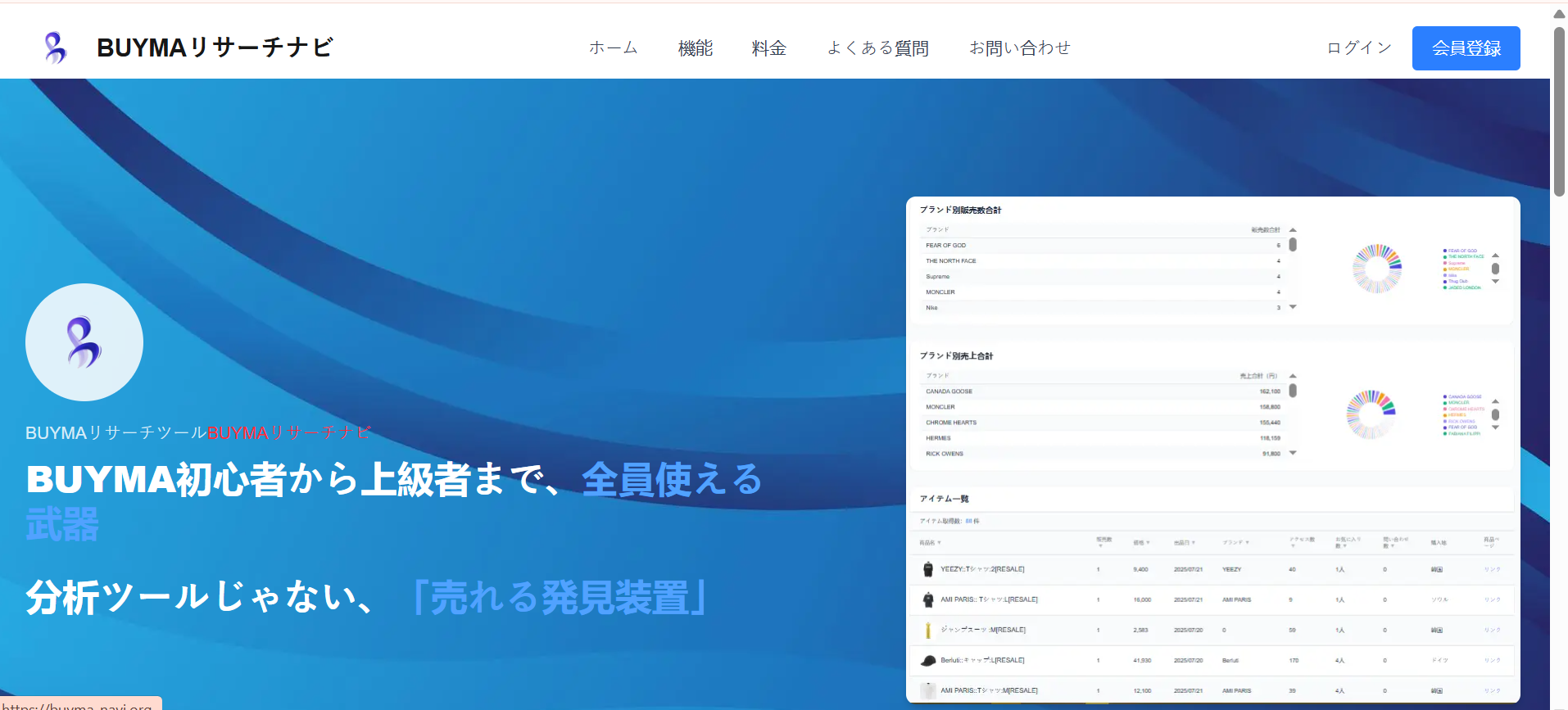
A focused research portal to collect, normalize, and analyze BUYMA listings. Backend: Python FastAPI + PostgreSQL. Frontend: Next.js for a fast, modern UI.
The system scrapes BUYMA product data, enriches it, and stores it in PostgreSQL for fast queries. A normalization layer resolves variants, brand names, and duplicates. Users can filter by price, brand, seller, or freshness—and export results for deeper analysis.
Highlights
- FastAPI workers with queue + retry; rotating proxies & backoff.
- PostgreSQL schema for products, variants, sellers, and snapshots.
- De-duplication, normalization, and change-tracking deltas.
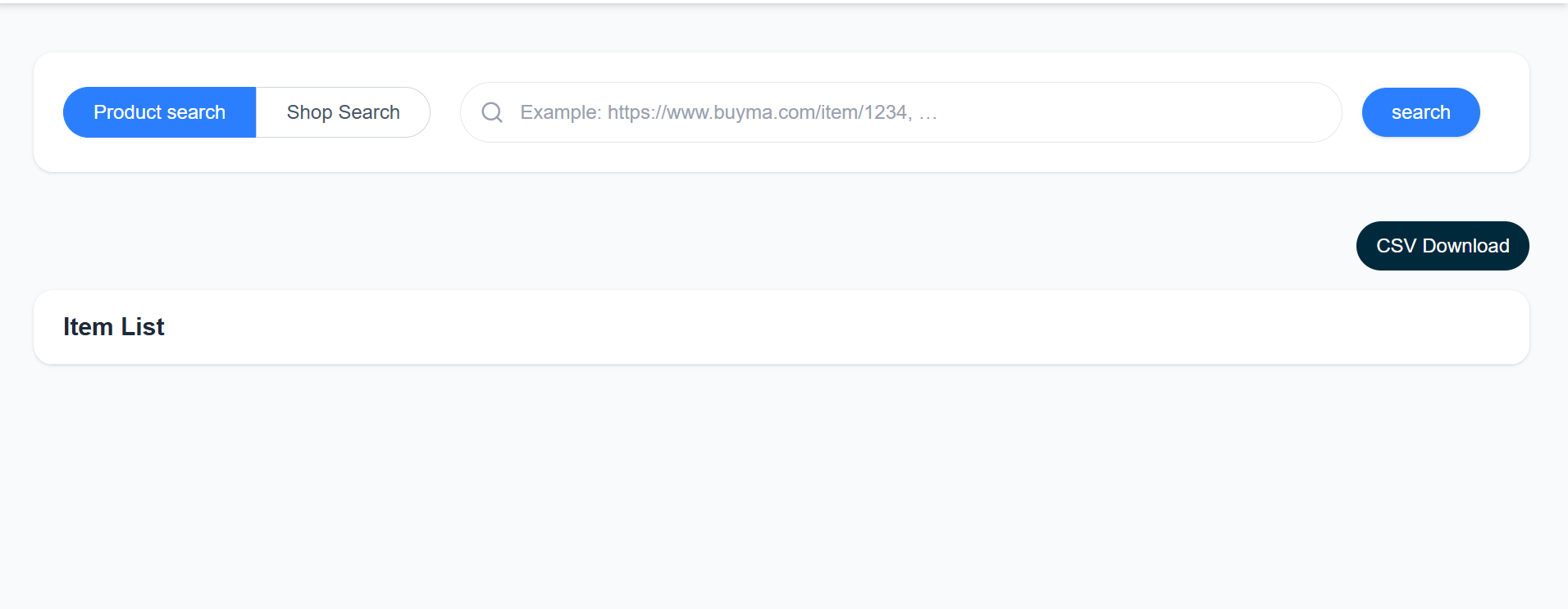
- Next.js UI with advanced filters, CSV export, and saved views.
- Robots/ToS safeguards, rate limits, and audit logs.
UI preview